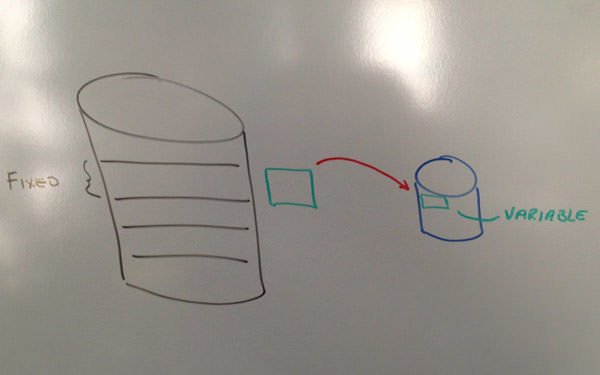
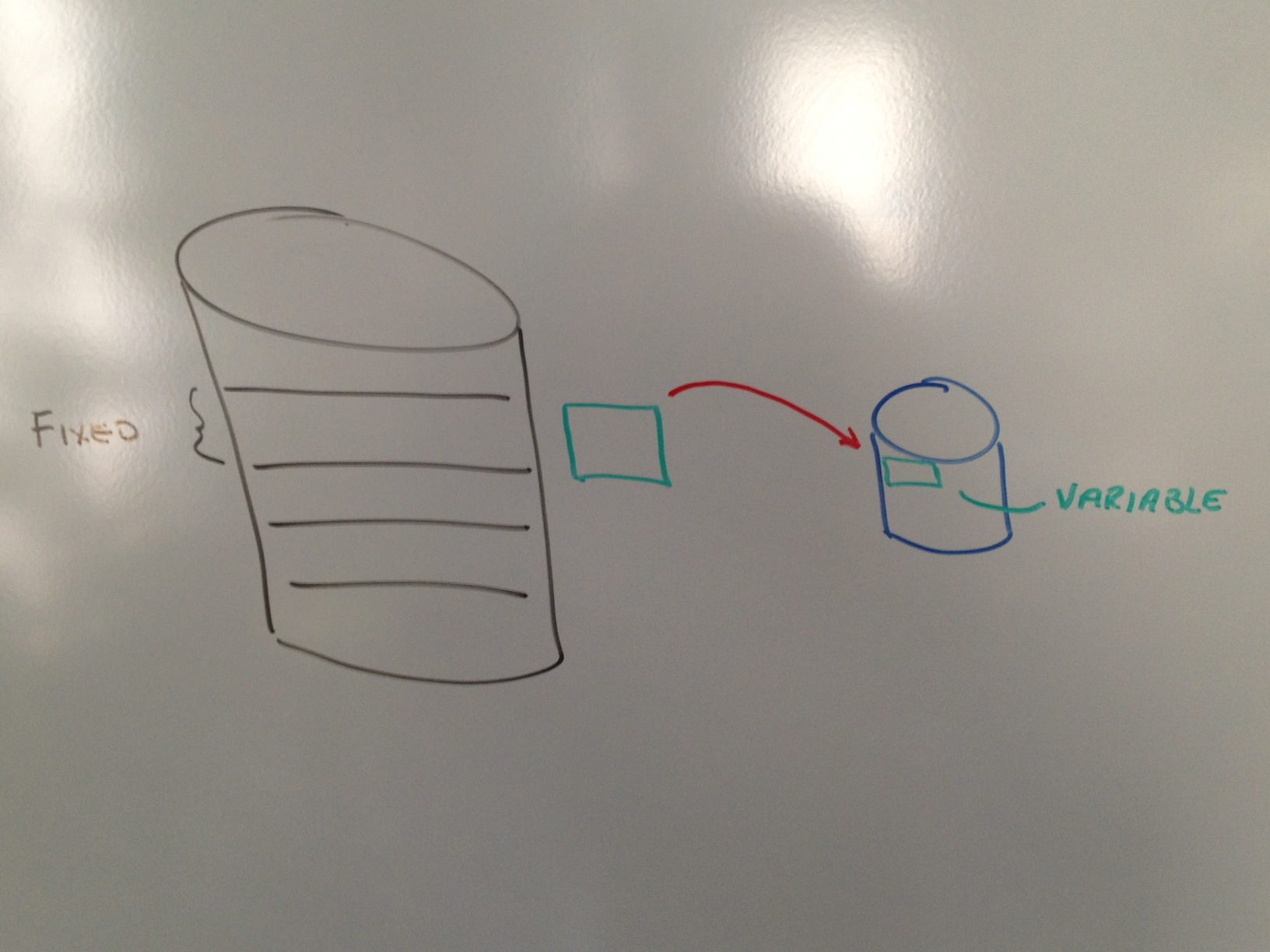
As a number of you know, I have been blogging about the merits of Real-time Compression. It may be of some interest to know that when Ed Walsh, CEO of Storwize, asked me to join and told me the company focused on "compression", I first thought he was joking. I mean the industry has had compression available for years. The reality is, there is no other technology like Real-time Compression available from any vendor, and it is today, even more clear, why IBM chose to own this technology. In the next few blog pieces I plan to talk about a few of the concepts of the IP that make this technology so far advanced than any / all of its competition. Today’s piece is about fixed input versus variable input compression. This is a very simple concept to understand really. Traditional compression uses a process called 'fixed input' / 'variable output'. If we refer to the diagrams below, we start off with the original file on the left and the compressed file on the right. The way traditional compression works (and you can actually watch this on your home computer if you winzip a file) is the following: The compression algorithm will 'chunk up' the original file into 'manageable' sizes before it compresses the file. The tradeoff here, and why this process happens, is like with anything in computer science, performance for optimization. The first diagram shows the large file being 'chunked up', compressed and stuffed into the smaller file.
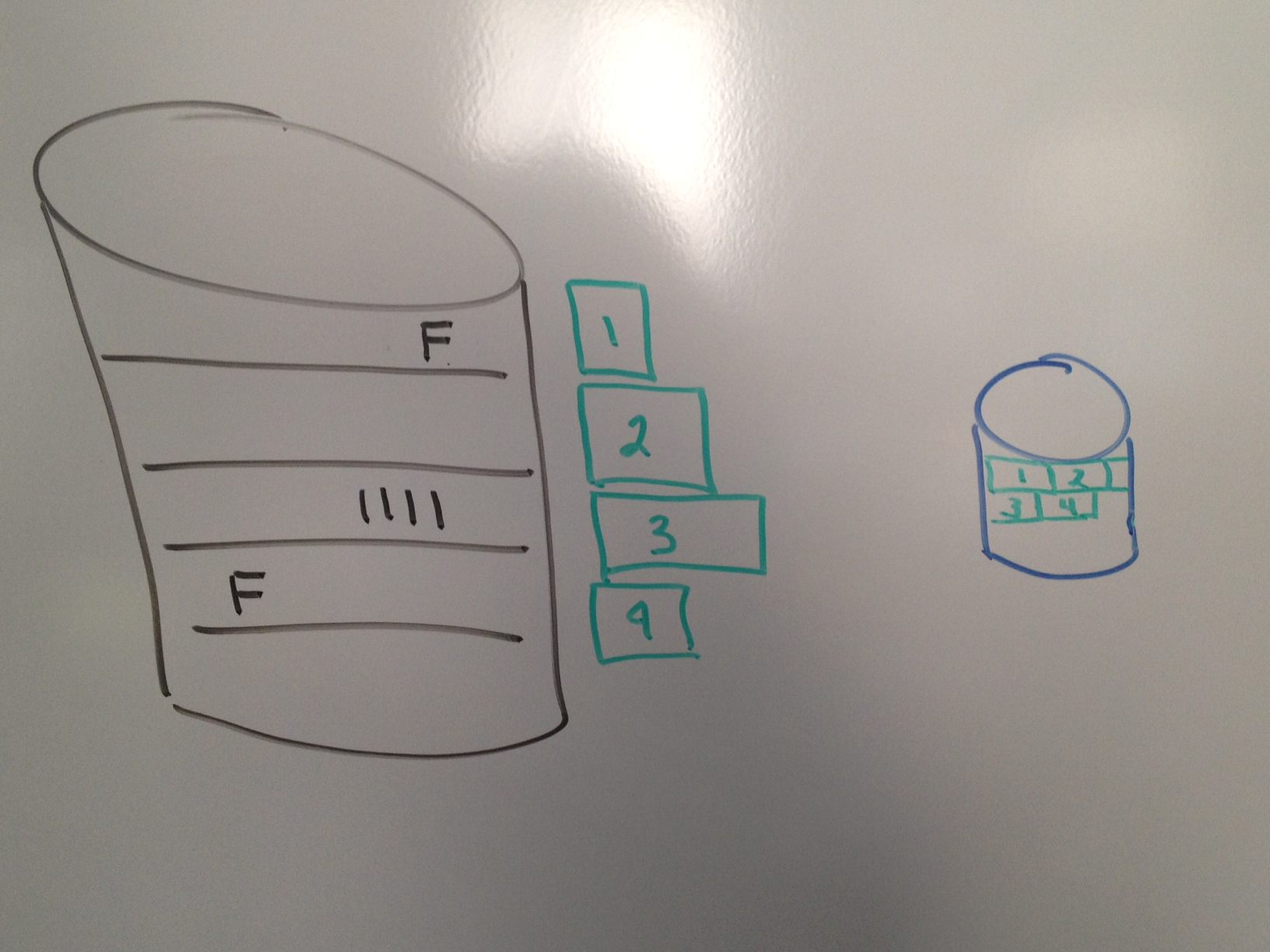
There are two significant issues with this. The first issue is that the compression dictionary is not shared across multiple ‘chunks’ when compression is taking place. The example in Figure 2 shows that the letter “F” in ‘chunk’ 1 does not get compressed with the letter “F” in ‘chunk’ 4. This means that the compression ratio is simply not optimized across the file.
Second is that as a file gets modified, and the compression ratio of the modified ‘chunk’ changes, it will cause fragmentation in the compressed file. Figure 3 shows ‘chunk’ 3 being updated from “1111” to “1100”. The newly compressed ‘chunk’ 3 is smaller (referred to as 3’). As the new compressed ‘chunk’ is added to the end of the file, a “hole” is left in the compressed file.
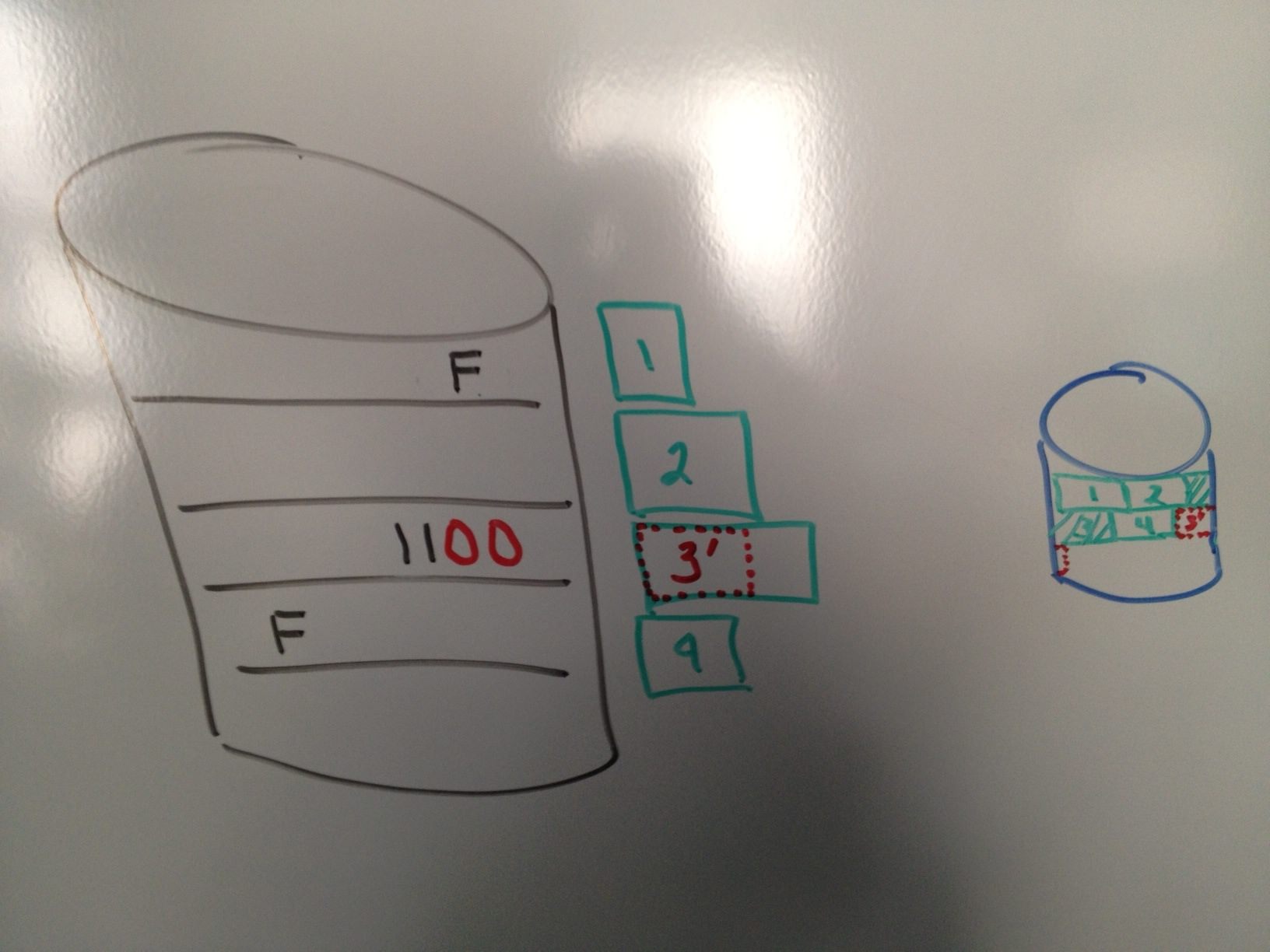
Best practices documentation from the competitors to Real-time Compression will tell users that if a file is frequently modified, that over time, the compressed file can actually be larger than the original file. This does not help the storage administrator.
- Over time the file system can grow rather than shrink which was the premise for using compression in the first place
- The I/O performance on the array will be very taxing
- The CPU cycles taken up on the array for compressing and decompressing these files will also be taxing on the array and cause a significant performance impact.
The converse to ‘fixed input’ / ‘variable output’ is ‘variable input’ / ‘fixed output’ and this is how Real-time Compression compresses a file. I should first note that because Real-time Compression operates as an appliance in NAS environments, in the network, we see the data stream into the array. By looking at the data stream as it enters the array we have the ability to do some very unique things. First, we are able to compress “like” data together. In the case where there are two “F”’s in the same file, we are able to leverage the same compression dictionary and obtain additional compression in the file. This is what is known as time based compression versus location based compression in the other scenario. This is how Real-time Compression is actually able to get up to 10% better compression ratios than its competitors.
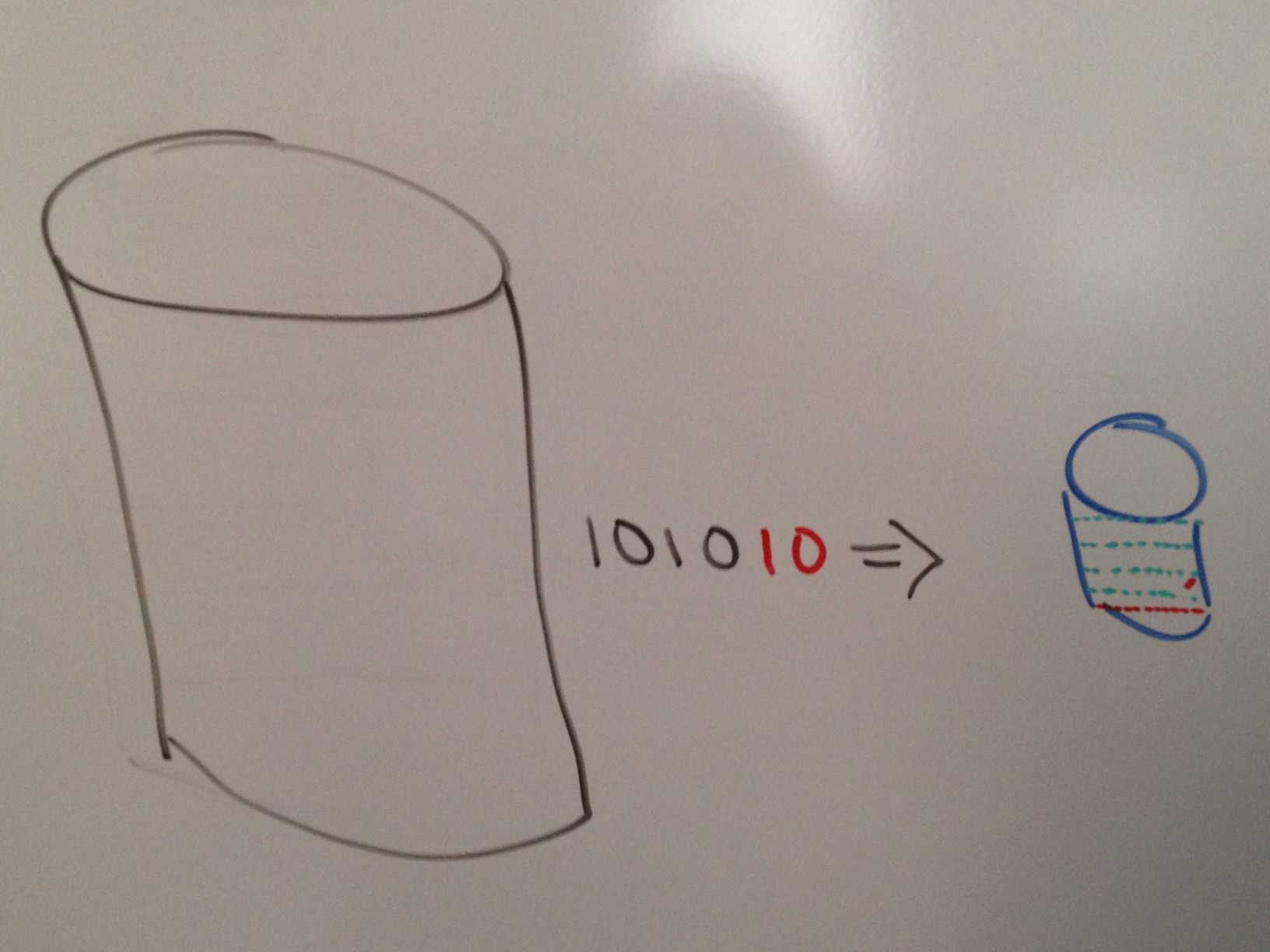
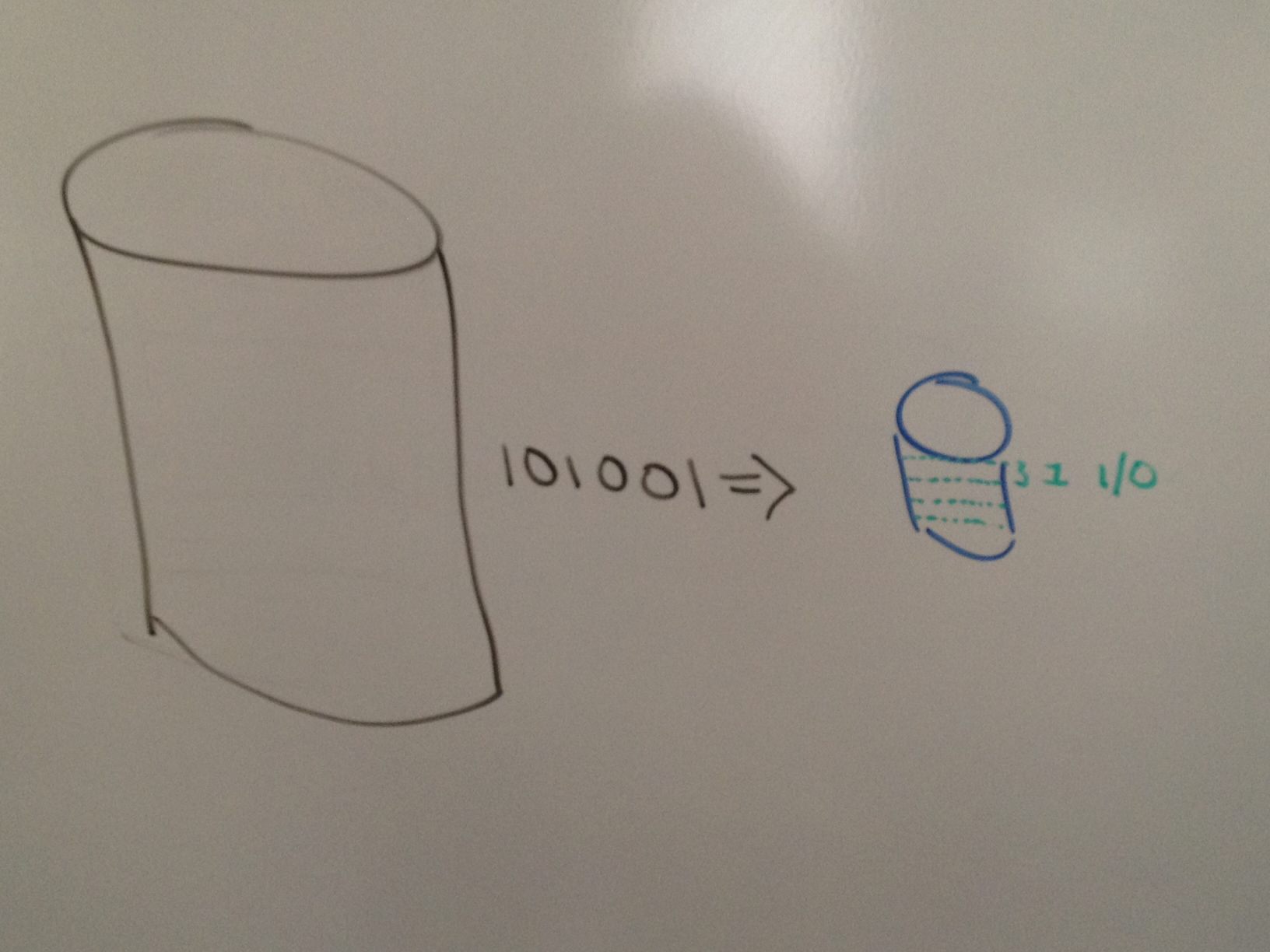
Having fixed segments in the output file also has added benefit. First, each segment in the output is the equivalent of 1 I/O. In an NFS environment the ‘chunk’ is 32KB in a CIFS environment the ‘chunk’ is 60KB. This means that any read from the file can be done in 1 I/O saving significant I/O resources when accessing a file. By maintaining an index of these segments (one in the cache of the appliance and a copy in the compressed file) Real-time Compression can eliminate fragmentation of the compressed file. When a file is modified, the modified compressed ‘chunk’ is flagged by the index that it is available for the next write to come in and the newly compressed ‘chunk’ is added to the end of the file. When the next modification comes in, the hole that was left by the last modification is now re-used. This means:
- The compression ratio is maximized by looking at a stream of data versus chunking it up
- The compression ratio for the compressed files stay the same throughout the life of the file saving IT the space they desperately need
- Lowering the I/O on the array helps to maintain / improve performance to the application
- Removing the CPU cycles and having the appliance do the work means that the array is not overloaded when trying to do compression
This is just one example of the over 35 patents leveraged in Real-time Compression. In an age where data growth is the single biggest challenge for IT, this technology has tremendous value to any companies business. Weather it is trying to reduce storage budget costs, reduce utility expense, have more data on line and available for analytics or reduce footprint on primary storage to product backup savings, this technology has many business benefits.
Stay tuned as I talk about another piece of the Real-time Compression IP.