
Let me get this straight, I am going to go back to my days of blogging about data deduplication? What?
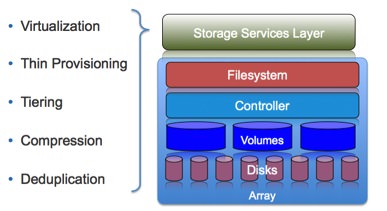
The reality is that data deduplication is really one of the latest technologies to become commoditized. More and more we are hearing about “Software Defined Infrastructure” or “Software Defined Storage”. This makes sense to me especially when you have the ability to start taking the specialty storage services such as virtualization, thin provisioning, and deduplication, and making them available to “all” storage. Today we are seeing vendors take solutions out of the array and put them into these platforms such as IBM’s SVC and EMC’s ViPER such that these services can be available to all storage in the environment, not just one array. (In the case of EMC it is still only all of EMC’s storage, but in the case of IBM with SVC, these services can be provided to heterogeneous storage.) I look at these platforms much like iOS and the storage service as the “app” for the iOS.
Data Deduplication
Data deduplication started in the backup world where you saw data over and over again making the technology very applicable. All investments, up until recently, have been for deduplication for data protection. It was fairly easy for this technology to take off in the data protection space for a number of reasons:
- Data growth in backup is 4x primary so trying anything to control this growth was worth a shot
- Backup isn’t necessarily a part of the “mission critical” stack (okay, some folks can argue w/ me – but business don’t make money on “backup” – well, unless they are a service provider)
- People have been saying “backup is broken” for so long, they are willing to try most anything - easy to take a risk
Today if your not running deduplication in your backup, your probably missing the boat and spending too much money.
There were several vendors who have/had deduplication solutions; Asigra, Avamar, Data Domain, Permabit etc… A number of the larger vendors acquired these smaller startups or built their own and it was the fact that they had different technologies and capabilities that was there “secrete sauce” or “competitive advantage” in the backup space. These technologies were designed for and operated well in staged, batch processed, large object/stream and dedicated appliance environments.
Now we fast forward to 2014. Data is growing faster than ever (we all know that) and storage efficiency features are becoming even more important on primary storage. In addition, “common” storage services, such as data deduplication, across the storage infrastructure is becoming the next step in storage savings. There are a couple reasons this is the case. First, disk areal density isn’t growing the way it did in the late 90’s early 2000’s. Additionally, with SSD technology, the $/GB is high and if there is anything I can do to drive that cost metric down and get a better $/GB, I want to do that.
Vendors who have deduplication solutions for backup are finding that delivering deduplication for primary storage is very complex. Deduplication for primary storage requires inline, random, extreme resource efficiency (many services competing for processor and memory), high performance and massive scale. By way of example, I worked for a company that sold “Real-time Compression” – data compression with no performance degradation. The ability to shrink your data set, allow applications to still use the data in compressed format and not have there be any performance penalty is essentially why IBM bought the technology. Deduplication needs to behave with no impact to performance. Additionally, primary storage deduplication needs to be smart. In backup, the data that is seen (typically files) is very redundant and is typically very common data (I make 10 copies of a power point presentation with one slide changed, there isn’t a lot of differences). With primary storage that isn’t always the case. We used to say at Avamar that dedupe would never be used for primary storage because there wasn’t enough redundancy to make it worth while (given the performance limitations at the time). Lastly, deduplication on primary storage needs to scale and be able to work across multiple arrays and data sets. Why? Because the act of rehydrating data and then deduping it again is an “expensive” process (performance wise). Arrays need to be able pass deduplicated data from array to array without having to rehydrate it and allow it to be used where it lands (lets say for DR, test/dev etc…)
All of the large vendors such as NetApp, EMC, HP, IBM have tried or are trying to develop deduplication for primary storage but are finding this difficult because of the complexity of the requirements. Upstarts such as Pure, Nimble, and Nutanix have built point solutions that aren't really inline but adding a lot of value. The ‘killer app’ today is the one that enables the preeminent products to offer both real-time compression and deduplicaton for primary storage at line speed. Interestingly enough, as time has moved forward, one vendor, Permabit understood these challenges and built an SDK that allows their technology to be implemented in an array or, more importantly, on a platform that would allow you to have this storage service across heterogeneous arrays. This is interesting because it can give vendors who choose to partner with Permabit the ability to quickly get to market with a solution that enable, real-time, efficient deduplication at scale. If you are a vendor looking to implement deduplication for primary storage and finding the investment a bit taxing, but you need it right away to compete, it makes sense to look at what Permabit could offer your company. They have been working with HDS, to some success I may add, helping to give them a competitive edge in a lot of instances.