
At one point during my days at IBM I had the title, Storage Efficiency Evangelist. My role was to help educate folks on the host of storage efficiency technologies that are available to help stem the tide of the data apocalypse.
Technologies such as storage virtualization and thin provisioning help with storage utilization. Tiering technologies help by placing the right data set, on the right storage tier. Data compression and deduplication help to reduce the overall storage footprint, further adding to the efficiency story. Leveraging these technologies, customers can reduce their overall storage footprint by as much as 60%.
However, these storage “services”, as I like to call them, don’t help you to understand what the data is or help manage what service should be applied to the data in order to maximize storage efficiency. These storage services also don’t tell you how you’re data really is exploding. In other words, it’s not just the fact that data is growing, but that it is also being copied via storage services such as snapshots, mirrors, clones, backup, archive and replication and that is causing massive data proliferation (see Figure 1). In 2013 IDC stated that as much as 60% of enterprise disk storage system capacity is made up of copies of data. Similar, in 2012, copy data made up nearly 85% of hardware purchases and 65% of the storage infrastructure software was used to store and manage these copies of data. Today there is a real need to get a handle on this data propagation problem.
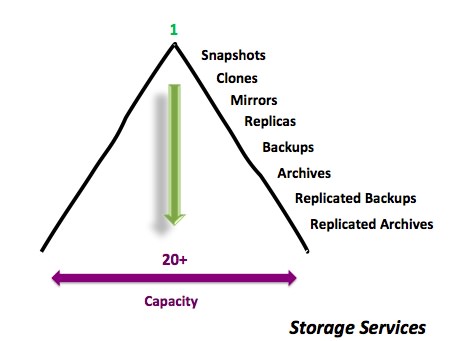
A few weeks ago I was speaking with a customer and they asked me, “So when is dedupe 3.0 going to be available?” What they were really asking is, “What is the next storage efficiency solution they should be taking advantage of to help them with their data explosion?” I talked to the the customer about tools that can help get a handle on the “copy data” problem, will be the next big thing for storage efficiency.
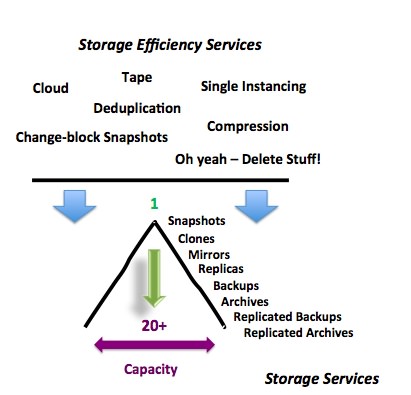
Some storage “efficiency” services such as compression and deduplication help to shrink the overall capacity, but it doesn’t help with the number of copies OR how the copies came to be in the first place (see Figure 2). New solutions are available today that can help with the “copy data” challenge. Properly tackling the “copy data” issue comes in two phases. First there is “Copy Data Management”. This is the ability to understand where all the data copies are in your environment as well as what they are and how they keep growing. As an example, understanding that you have 23 snapshots for the protection of data one volume and half those snaps are orphaned is over kill, a waste of space and says there is probably a bad snapshot policy somewhere. Additionally, IT is always in data migration mode. It makes a lot of sense knowing what data you have and where it is so it can be cleaned up before migrating it. Moving excess data is a waste resources. Its like doing the yard sale after you move not before. Not to mention it helps to figure out what policies may need to change in order to store data more efficiently in the new environment.
The second phase is “Copy Data Services”. Copy Data Services can help you control both the size of the storage pile but also the number of objects in the pile (see Figure 3). Now that you’re data house is in order, all of the copies are accounted for and you have deleted or migrated the excess, it is time to put a solution in place that doesn’t cause the copy data problem in the first place. A solution that is tied closer to the application is the right place to start. The proper solution is one that can enable snapshots, which is a trend for data protection, as well as enable other storage efficiency solutions such as deduplication and enable data availability such as DR with services such as replication.
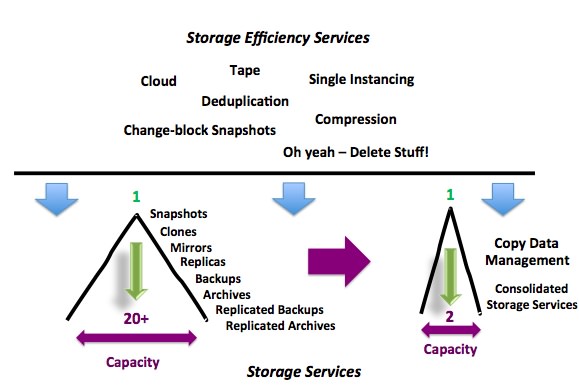
Additionally, providing the ability to leverage this copy of data for multiple purposes by simply mounting a snapped copy eliminates the need for making additional copies of the data for file recovery, test & development or analytics. This helps to cut storage costs and save storage management time and expense.
So if your looking for the next generation of storage efficiency services to add to the storage infrastructure that can save time and money, Copy Data Management and Copy Data Services is De-Dupe 3.0.
For more info, watch this short video: